Improving DX and foundation on Boba Life
I’m pretty ambivalent about the project, but since my spare time is so unpredictable, I’m continuing to iterate on Boba Life, as it has enough structure and freedom to keep learning and trying things with at least a semblance of real users and stakes. I’ve slowly been bringing the website more up to date so that users have a place to show all of their drinks, and hopefully it will afford some richer data visualization in the future.
The web app runs on Next.js and as of the last month, uses Tailwind, Shadcn/ui, and Next’s app router (instead of the pages router). I can’t believe it took me so long, but I’m now running Prettier on all files on pre-commit. (Wow, I had to learn a lot of CSS again to adopt Tailwind, and I spent a bit of time trying to actually learn CSS Grid for real since I only really used Flexbox - CSS has improved a lot since I last looked!). This is on top of the Prisma migration I did earlier this year (documented in this blog post, which greatly reduced my AWS bill and simplified development since it involved a migration to SQLite).
The main profile page (https://boba.life/david) now looks like this:
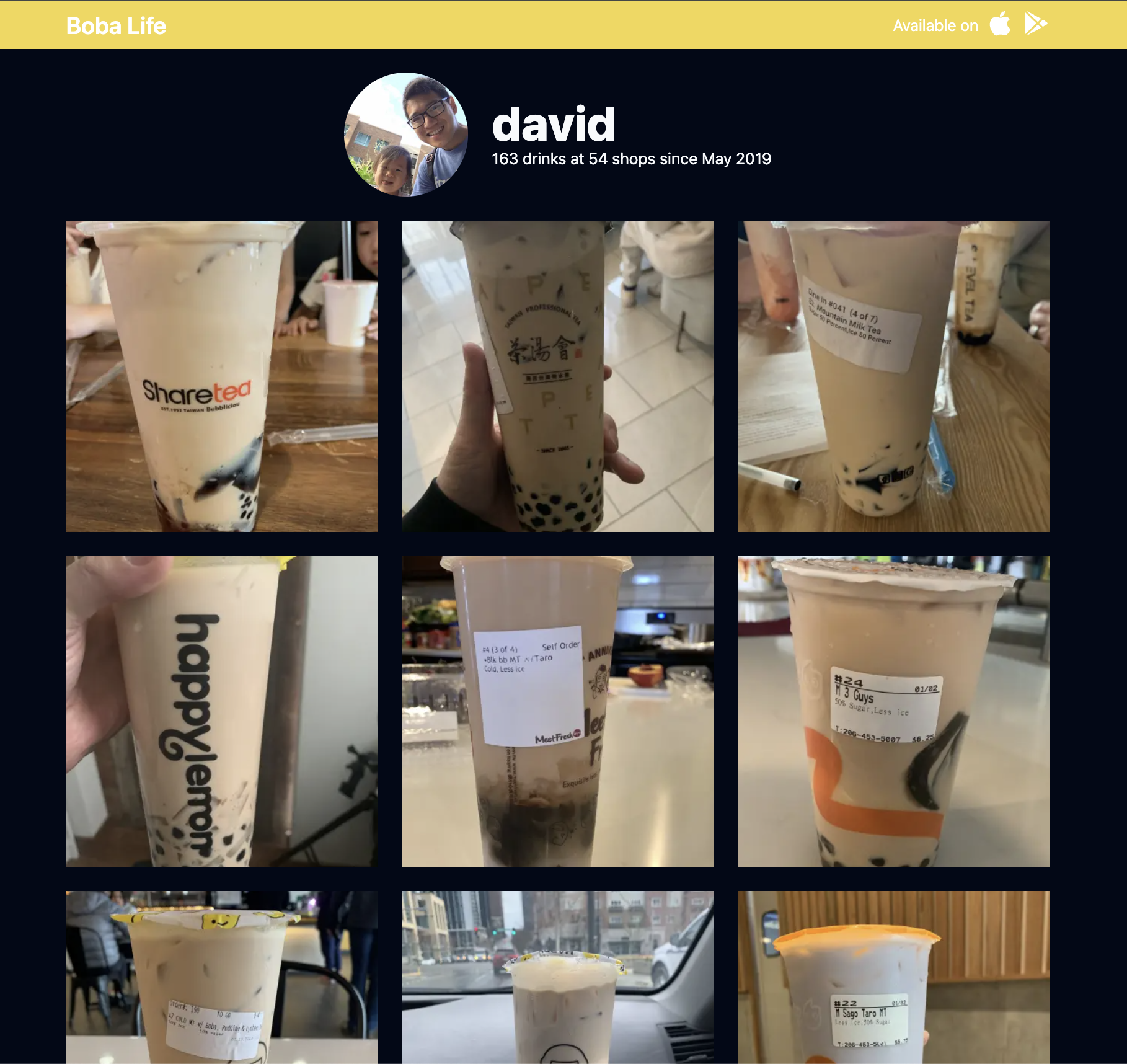
And the new drink page looks like this:
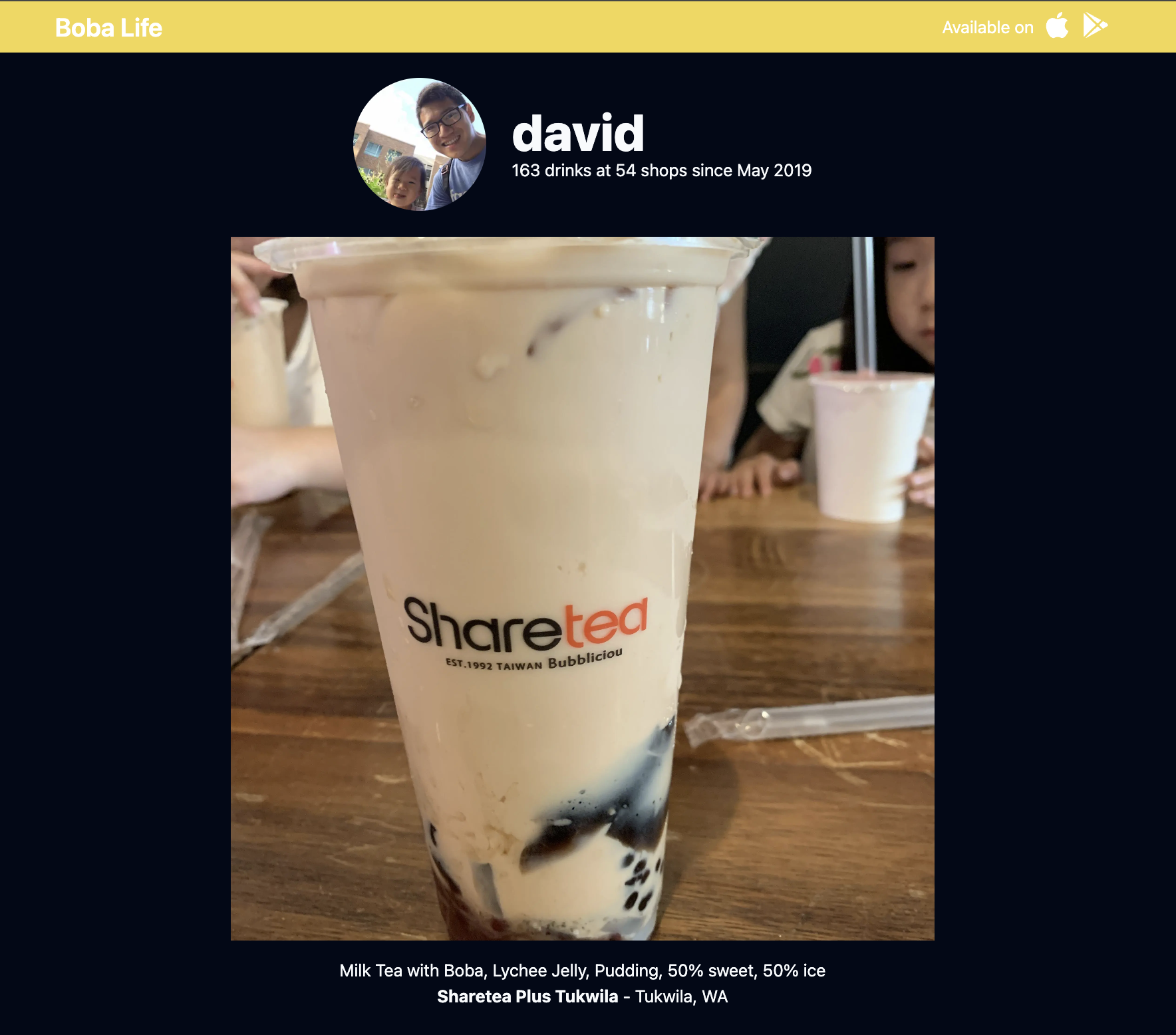
I also finally upgraded my DigitalOcean server so that I can run a more up-to-date version of Node. My original server was 6 years old, couldn’t get up to Node 20, and had a bunch of old stuff that I had originally manually set up - I didn’t realize DigitalOcean had a “marketplace” of preconfigured, common images (I used this basic Node one) which came with Node, Nginx, and PM2 out of the box (though in a similar vein, I tried setting up a Ghost blog image as well and had trouble ever getting it to work). I had to set up SSL again, but that wasn’t bad on a fresh server (old documentation in this blog post came in handy), and then I used DigitalOcean to switch my DNS records to point to the new server (which conveniently populates with your DigitalOcean servers, so there’s a lot less cognitive overhead involved).
The migration to Next’s app router allowed me to use real React Server Components, and it was a relatively simple migration since I only had two real routes (user and post). It seems like you don’t need to migrate to the app router if you don’t want to, but it provided some nice benefits to me in a rather constrained use case:
- Simpler file organization - Since routes are defined by explicit page.tsx files, I could get rid of a separate components directory that I had and colocate components with their callers
- No intermediate data types - With the older getServerSideProps , I’d have to serialize certain types of objects (especially dates). Since RSC can make data fetches directly within the component, I don’t need to worry about data serialization (being able to reuse TS types in the process)
- Easier to share layout code, so it reduced the amount of copy/paste I had been doing previously
- I believe adopting React Server Components unlocks a really nice “instant loading” state for pages. You can define a component in
loading.tsxfile and that will be rendered until your RSC asynchronously streams the data in. I used Shadcn’s Skeleton component (placeholders with a nice glimmer effect). (To develop that, I just awaited a 10 second Promise in my RSC to have a long enough time to see the Loading UI. I matched the sizes and made sure there wasn’t a visual shift when the data actually loaded. I defined and exported distinct Loading components in the same file as their actual component implementations to make it harder to change one component without forgetting the Loading component. I considered handling both the Loading and Loaded behavior within the same component, and that could have been reasonable, but I didn’t want to have to make my types undefined-able).
I also exposed a route to view specific drinks (eg https://boba.life/david/UziHT3). Previously, my posts table in the database had only been using an autoincrementing integer ID. I didn’t want to make it so easy to see how many posts had been created in the database (the concern was more on knowing how many posts had been created than scraping - it should be a little harder to scrape since the username also needs to be provided in the URL). I ended up adding a new string column called uuid in the posts table (through Prisma), and then backfilling the column with strings generated through the short-unique-id library (a little nicer than using some sort of native cryptographic function like randomUUID that might need some additional massaging).